Neural networks
Neural networks (NN) are algorithms used to detect information and conclusions from large sets of data by recognizing underlying relationships in sets of data the same way a human brain does. They hold a tremendous amount of potential for deep learning, part of a broader family of machine learning (ML) methods based on learning data representations, as opposed to task-specific algorithms. NN and deep learning are now computationally feasible due to GPUs, it shows unbeatable power on complex prediction problems that have very high dimensionality and millions-billions of samples.
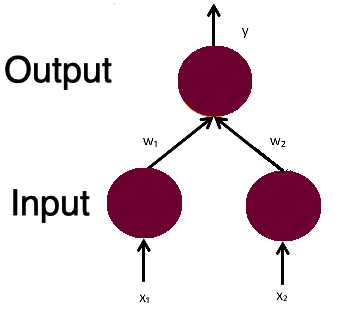
However, for smaller scale problems this approach would likely be an overkill. Designing, building a NN, tuning hyperparameters, etc., requires specific experience and skills and time. In many cases it can not be justified even by a gain in model’s performance. Besides, it is not correct to juxtapose the two, because NN are part of ML. NN are designed to solve particular classes of problems, they are not universal solvers. In some cases even ML is overkill and a statistical test could be sufficient, for example.
Let’s say that you have a problem to model in order to make accurate predictions. We always kind of have an intuitive sense of the variables or parameters of this model. Learning is all about fitting a set of parameters to some data such that it can reproduce the data accurately. From traditional statistics to machine learning to deep learning, that’s always what’s being done.
How many parameters do you think would be able to model such a probability? A lot? A few? It’s a trivial example, but the same applies for less trivial ones where we know the numbers of parameters is limited, e.g. predicting the maximum speed of a car (weight, engine type, fuel, etc.). For these problem, it clearly looks like statistics would be able to fit the data. It seems linear, and relying on a few parameters only. Now, you want to classify emails whether or not they’re spam. How many parameters? Some words can help defining this is spam, sure, but do you have a full list?
 I can also send spam by using a very standard language, without forcing you to buy or putting many links. It looks like the model will be richer than simply a few parameters. In fact, it looks like machine learning would help to learn a few hundred parameters to really be able to model what is a spam email.
I can also send spam by using a very standard language, without forcing you to buy or putting many links. It looks like the model will be richer than simply a few parameters. In fact, it looks like machine learning would help to learn a few hundred parameters to really be able to model what is a spam email.
Now you want to recognize faces on pictures. How complex do you think it is? Do all eyes look the same? Mouth? Skin color? Hair shape and color? Elements like eyes, nose and mouth only make sense when they are put together in a meaningful way (unlike Picasso who likes to paint them). See, it looks like while our brains do it very easily, it’s really hard to grasp what makes a face. It’s a very complex and rich model that will be needed here, able to model many potential faces to efficiently recognize them.
Deep learning is most likely to yield better results than the previous approaches. Finally, if you select an approach too big for the task, you will simply overfit the data and spend way too much time building a complex approach for no benefit, quite the contrary.